The essence and applications of word2vec technique
The word2vec technique has become an essential part when building a text model and even adapted in other fields like building a recommendation system. In this blog, I will introduce the basic concepts and applications of word2vec.
When building a machine learning model to understand text, the first challenge is to encode the text as numerical values. Naively, we can encode each word in the vocabulary with a one-hot vector. The length of the vector is the same as the size of the vocabulary and the distance between any two words is the same. At this point, a question might come to your mind: is it sensible to let distances between synonyms and those between antonyms be the same? Definitely not. Besides, one-hot encoding usually has a very high dimension. A more reasonable embedding should preserve semantic and syntactic similarity, relation with other words, etc. e.g. The words “president” and “Trump” should be close to each other in the embedding space; the distance between “woman” and “man” should be similar to the distance between “aunt” and “uncle”.
How do we formulate this problem from a machine learning perspective? word2vec was initially implemented by a continuous bag-of-word model (CBOW) [1], which predicts the next word given one word using a shadow feedforward neural network (Fig. 1). When training CBOW, each word is represented by a one-hot embedding as we don’t have the desired embedding at this point. The CBOW takes a word, transforms the one-hot encoding of that word into a new embedding space and finally predicts the probability of each word in the vocabulary. When the learning process converges, the former part of the CBOW model is able to generate a semantic embedding for each word. In the setting of CBOW, the input word is the context of the predicted word. In practice, the context is multiple words. The way CBOW defines the learning task for the model is similar to fill-in-the-blank quizzes. Note that a CBOW model is trained in a supervised way but to generate word2vec no labeled data is needed because the context-word pair can be generated without human labels.
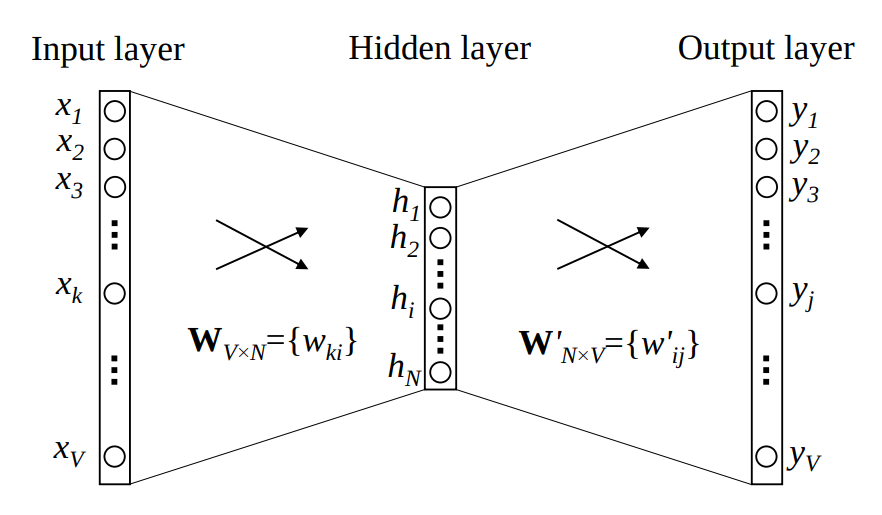
Fig. 1. A simple CBOW model with only one word in the context. In such a setting, the vocabulary size is V, and the hidden layer size is N [2].
Interestingly, the idea of inferring the meaning of a word from its context is applicable when building a recommender system. In the context of modeling a user’s behavior, a sequence of his/her activities is a counterpart to text and each activity to word. To make this idea more concrete, suppose we are recommending music to a user. A sequence of songs a user listens to can be thought of as a sentence and each song as a word. So we can create an item2vec [3] to represent each song and “item” here represents a song. In fact, this idea has lead to a big success commercially [4].
References:
[1]. Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013.
[2]. Xin Rong, “word2vec Parameter Learning Explained”. https://arxiv.org/pdf/1411.2738.pdf
[3]. Oren Barkan, Noam Koenigstein. “Item2Vec: Neural Item Embedding for Collaborative Filtering”. https://arxiv.org/vc/arxiv/papers/1603/1603.04259v2.pdf
[4]. Grbovic, Mihajlo, and Haibin Cheng. “Real-time personalization using embeddings for search ranking at Airbnb.” Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018.